App-Log Queries with Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases provides a fully managed Retrieval Augmented Generation (RAG) experience for businesses. This knowledge base can then be used to augment responses from foundation models through a popular technique called RAG. This helps in generating responses that are not only more accurate but also more tailored to the specific needs of your business.
In this blog post, I will explain how Knowledge Bases for Amazon Bedrock with Pinecone, managed vector database on the cloud to query the details of application log files.
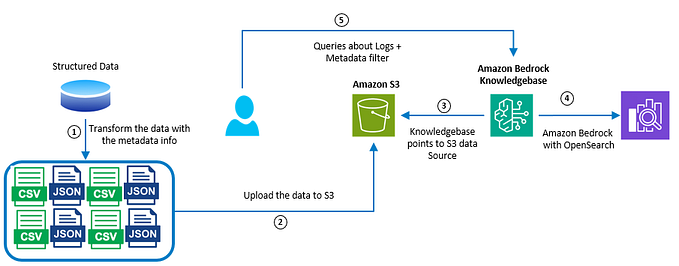
Solution Diagram:

The solution has two part:
1 — Knowledge base indexing and synchronisation
2 — Retrieval and generation
Solution Component :
Knowledge base indexing and synchronisation:
- Creation of Pinecone Index:
Pinecone index need to be created to store the vector embeddings. This can be done by signing up to Pinecone console and create your Pinecone index, and retrieve your index’s endpoint and apiKey from the Pinecone console.

Create a API Key in the Pinecone which will be used by Knowledgebase to access vector DB.

Store the apiKey in AWS Secrets Manager:

Choose Other type for Secret type and set ‘apiKey’ as the key. Fill your Pinecone api key in the value box. This Secret ARN is required when creating Bedrock Knowledge Base.
2. Creation of Knowledgebase:
Knowledge Bases for Amazon Bedrock enable you to ingest and store data sources into a central repository of information. Once you have pointed to your data in Amazon S3, Knowledge Bases for Amazon Bedrock automatically fetches the data, divides it into blocks of text, converts the text into embeddings, and stores the embeddings in your vector database.
To enhance data retrieval, the log files are divided into smaller segments, converted into embeddings, and stored in a vector index, maintaining a link to the original document. These embeddings enable semantic similarity comparisons for efficient query matching in data sources. This process is depicted in the accompanying image.

Creating the knowledge base involves the below key components:
- DATA SOURCE
Accepts a single S3 bucket as a data source , which holds the application log files - EMBEDDINGS MODEL
Titan Embeddings G1 — Text v1.2. - VECTOR DATABASE
Choose an existing vector database, Pinecone index will be used for this use case
I will use the Amazon Bedrock Console to configure the knowledge bases, this can be found in Buider tools option within the Amazon Bedrock console as shown below:

Configure the data source : The data source dictates how the content will be ingested, including the storage configuration and the content chunking strategy.

configure Embedding model & Vector Store


Select the data source and click the sync:

3. Synchronize the dataset with the knowledge Base
As the logfiles will be uploaded to the S3 bucket at regular interval, the Knowledge Bases need to be sync with the uploaded data, this can be done using S3 upload event notification invoking a AWS Lambda function to sync data
Creating S3 Notification on upload of log files : This can be done from the console using S3 bucket Properties and navigate to Event notifications and create an event notification on the put operation

Invoke a AWS Lambda function on the upload event , I have given a sample Lambda function to sync the Knowledge Bases

Sample AWS Lambda Function to sync the Knowledge Base, replace the DATASOURCEID & KNOWLEDGEBASEID with the details created earlier:
import os
import json
import boto3
bedrockClient = boto3.client('bedrock-agent')
def lambda_handler(event, context):
# TODO implement
print('Inside Lambda Handler')
print('event: ', event)
# Datasource
dataSourceId = os.environ['DATASOURCEID']
# Knowledge base id where to be updated
knowledgeBaseId = os.environ['KNOWLEDGEBASEID']
print('knowledgeBaseId: ', knowledgeBaseId)
print('dataSourceId: ', dataSourceId)
response = bedrockClient.start_ingestion_job(
knowledgeBaseId=knowledgeBaseId,
dataSourceId=dataSourceId
)
print('Ingestion Job Response: ', response)
return {
'statusCode': 200,
'body': json.dumps('response')
}Retrieval and generation :
4. Query the knowledge base with Streamlit :
We will create a conversational chatbot using Streamlit, by leveraging the knowledge bases. We can utilize Streamlit’s chat elements to construct an interactive user experience. We will use the RetrieveAndGenerate API to test the knowledge base. Behind the scenes, RetrieveAndGenerate API converts queries into embeddings, searches the knowledge base, and then augments the foundation model prompt with the search results as context information and returns the FM-generated response to the question. For multi-turn conversations, Knowledge Bases manage short-term memory of the conversation to provide more contextual results.
import boto3
import streamlit as st
st.subheader('RAG Using Knowledge Base from Amazon Bedrock')
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
for message in st.session_state.chat_history:
with st.chat_message(message['role']):
st.markdown(message['text'])
bedrockClient = boto3.client('bedrock-agent-runtime')
def getResponse(query):
knowledgeBaseResponse = bedrockClient.retrieve_and_generate(
input={'text': query},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'Knowlegebaseid',
'modelArn': 'modearn'
},
'type': 'KNOWLEDGE_BASE'
})
return knowledgeBaseResponse
query= st.chat_input('Enter you query here...')
if query:
with st.chat_message('user'):
st.markdown(query)
st.session_state.chat_history.append({"role":'user', "text":query})
response = getResponse(query)
# st.write(response)
answer = response['output']['text']
with st.chat_message('assistant'):
st.markdown(answer)
st.session_state.chat_history.append({"role":'assistant', "text": answer})
if len(response['citations'][0]['retrievedReferences']) != 0:
context = response['citations'][0]['retrievedReferences'][0]['content']['text']
doc_url = response['citations'][0]['retrievedReferences'][0]['location']['s3Location']['uri']
#Below lines are used to show the context and the document source for the latest Question Answer
st.markdown(f"<span style='color:#FFDA33'>Context used: </span>{context}", unsafe_allow_html=True)
st.markdown(f"<span style='color:#FFDA33'>Source Document: </span>{doc_url}", unsafe_allow_html=True)
else:
st.markdown(f"<span style='color:red'>No Context</span>", unsafe_allow_html=True)Conclusion :
Integrating the log files with Amazon Bedrock significantly enhances the capabilities of your RAG applications to query useful information about application log analysis .we’ve enabled a powerful RAG system capable of retrieving highly relevant information for augmented generation tasks. With the use of Amazon Bedrock Knowledge Bases you can effortlessly integrate and manage data from various sources, empowering your applications to deliver more informed and contextually rich outputs.